1. 什么是强/弱一致性?
对于分布式系统而言,一致性是探讨当前系统内的一份逻辑数据存在多个物理的数据副本时,对其执行读写操作会产生什么样的结果。在数据库领域,“一致性”与事务密切相关,又进一步细化到ACID(原子性、一致性、隔离性和持久性)四个方面。
在讨论分布式数据库的一直性时,实质上是在讨论数据一致性和事务一致性两个方面。
1.1 数据一致性
分布式存储系统为了避免设备与网络的不可靠带来额的影响,通常会存储多个数据副本。逻辑上的一份数据同时存储在多个物理副本上,当同时存在读操作和写操作时就带来了数据一致性问题,所以多个副本数据上的一组读写策略被称为“一致性模型”,本文提到了状态一致性和操作一致性两个概念。
- 状态一致性:数据的实际状态所体现的一致性;
- 操作一致性:外部用户通过协议约定的操作,能够读取到的数据一致性,即用户感受到一致性,实际存储并不一定具有一致性。
从状态一致性视角看,在任何情况下数据只有两种状态,所有副本一致或者不一致。在某些条件下不一致的状态是暂时的,还会转换到一致的状态,那么这种不一致称为“弱一致性”,变更操作后数据一直是一致的则称为“强一致性”。
2. 强一致性
例如MySQL的全同步复制模式,在该模式下用户与MySQL交互,主库和备库同binlog时,主库只有在收到备库的成功响应之后,才能够向客户端反馈提交成功。因此在用户获得响应时,主库和备库的数据副本已经达到了一致,所以后续的读操作肯定不会出现问题,这种模式称为强一致性。
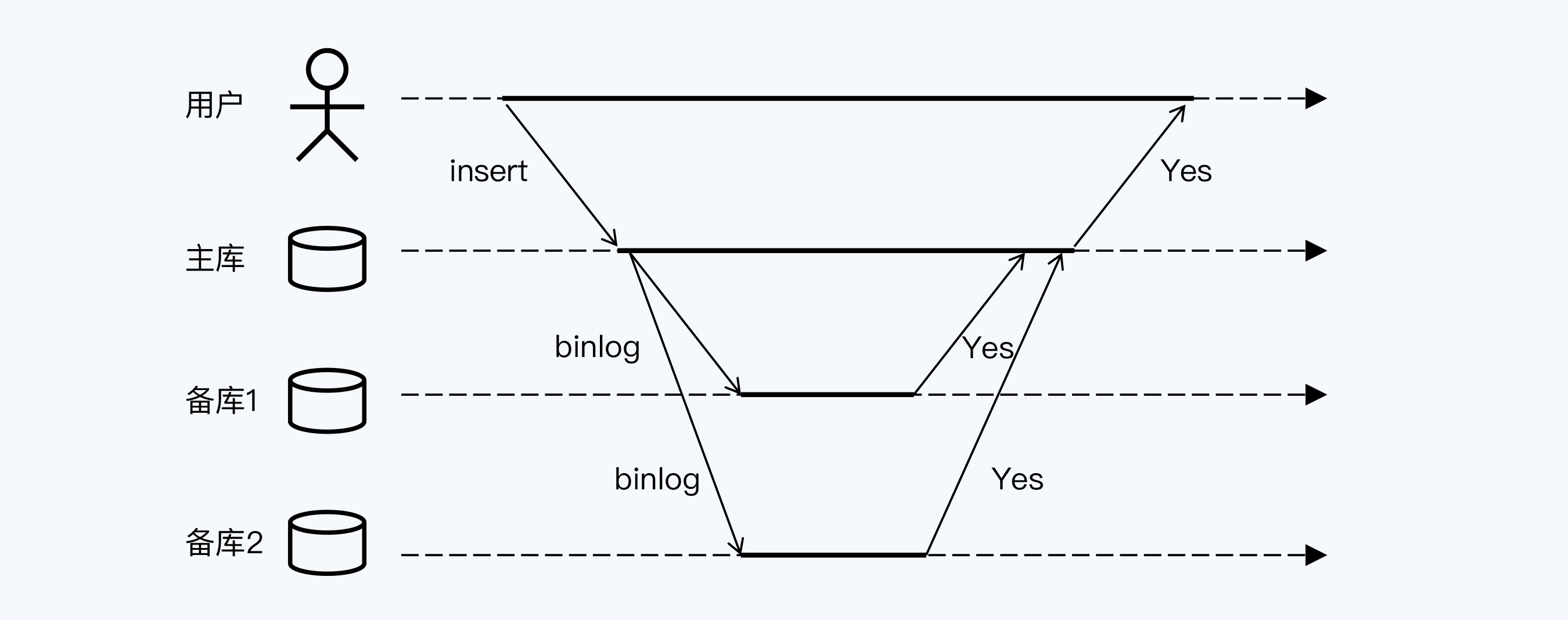
但是该模式具有很严重的弊端:
- 性能差。主库必须等到所有备库均返回成功后,才能向用户反馈提交成功。
- 可用性降低。在全同步复制模式下,集群中的节点被串联在一起,集群整体的可用性就降低了,且集群越大可用性问题越严重。
正因为这两个问题,实现强一致性需要的代价太大,所以大部分产品选择弱一致性。
3. 弱一致性
NoSQL 产品是应用弱一致性的典型代表,但对弱一致性的接受仍然是有限度的,这就是 BASE 理论中的 E 所代表的最终一致性(Eventually Consistency)。
最终一致性可以理解为,在主副本反馈给用户操作成功时,不要求其他副本状态一致,但在经过一段时间后这些副本最终会合主副本一致。而最终一致性的实现就需要从操作视角来分析。
4. 操作视角的一致性模型
4.1 写后读一致性
定义: 写后读一致性也称为读写一致性,写入成功的任何数据,下一刻一定能读取到,其内容保证于自己最后一次写入完全一致。
4.2 单调读一致性
定义: 一个用户一旦读到某个值,不会读到比这个值更旧的值。
写后读一致性是存在问题的,例如在向主副本写入数据,在主副本还未与从副本同步数据这个时间段中,用户B向主副本发起请求,成功读取到了数据;用户B再次刷新向从副本发起请求,这时候由于从副本数据同步还未完成,就出现了读取不到数据的问题。
这时候就需要单调读一致性的方式来解决这个问题,可通过将用户与副本建立固定映射关系实现,用户只能向固定的副本发送请求,避免了在多个副本中切换。
4.3 前缀一致性
定义: 前缀一致性又称为前缀读一致性,在数据上增加一种显式的因果关系,系统可以据此控制数据在其他进程中的读取顺序。
在更复杂的场景下,单调读一致性还是存在问题的,例如有3个用户,他们分别映射三个节点,用户A首先向节点A写入数据,其后用户B向节点B写入数据,由于网络等的影响,可能节点B在节点A之前向节点C同步了数据,这样节点C存储数据的顺序并不是数据实际的顺序。此时用户C向节点C读取到的数据就是错误顺序的数据。
前缀一致性解决了这样的问题,但是在很多场景下因果关系不是那么明显,不可能全部要求做显式声明。对于分布式数据库也不可能每次修改数据都附带声明本次变更是因为什么导致的。
4.4 线性一致性
定义: 建立在事件先后顺序之上,所有操作被记录在一条时间线上,并且原子化,让任意两个事件都可以比较先后顺序。
但是集群中各个节点不能做到真正的时钟同步,要将操作记录在一条时间线上就需要一个绝对时间(全局时钟)。工程实现上多数产品采用单点授时(TSO),也就是说从一台配有高可靠性设计的时间服务器获取时间,因此TSO有部署范围上的限制。另一种方式是通过GPS和原子钟实现全局时钟(TrueTime),可以保证全球范围内任意节点取得时间误差在7ms以内。
但是时间是相对的,不同的观察者可能对哪个事件先发生时无法达成一致的,因此线性一致性具有局限性。
4.5 因果一致性
线性一致性需要依赖绝对时间,还不够完美,因果一致性就是一个不依赖绝对时间的方法。
因果一致性的基础是偏序关系,也就是说部分事件顺序是可以比较的,至少一个节点内部的事件是可以排序的(依靠本地时钟),节点间的通讯事件也是可以排序的,接收方的事件一定晚于调用方的事件。基于这种偏序关系提出了逻辑时钟的概念。
借助逻辑时钟可以建立全序关系,但是这个全序关系还是不够精确的,因为如果两个事件不相关,那么逻辑时钟给出的排序是没有意义的。因此因果一致性弱于线性一致性,但是在并发性能上具有优势,也足以处理多数的异常现象。
5. 事务一致性
5.1 什么是BASE?
- BA 表示基本可用性(Basically Available):指某些部分出现故障,系统的其余部分依然可用。
- S 表示软状态(Soft State):是指数据处理过程中,存在数据状态暂时不一致的情况,但最终会实现事务的一致性。
- E 表示最终一致性(Eventual Consistency):指单数据项的多副本,经过一段时间,最终达成一致。
BASE 的意义只在于放弃了 ACID 的一些特性,从而更简单地实现了高性能和可用性,达到一个新的平衡。
5.2 ACID定义
- 原子性(Atomicity):事务中的所有变更要么全部发生,要么一个也不发生。在分布式架构下支持原子性并不简单。
- 一致性(Consistency):事务要保持数据的完整性,从一个一致状态到另一个一致状态。
- 隔离性(Isolation):多事务并行执行所得到的结果,与串行执行(一个接一个)完全相同。事务中最复杂的特性,隔离性分为多个隔离级别,较低的隔离级别就是在正确性上做妥协,将一些异常现象交给应用系统的开发人员去解决,从而获得更好的性能。
- 持久性(Durability):一旦事务提交,它对数据的改变将被永久保留,不应受到任何系统故障的影响。是数据库的基础,核心是如何应对系统故障,系统故障可以分为两种
- 硬件无损、可恢复的故障:常见解决方法是预写日志(Write Ahead Log, WAL)保证第一时间存储数据。
- 硬件损坏、不可恢复的故障:采用日志复制技术,将本地日志及时同步到其他节点。
5.3 事务隔离性
事务模型的发展过程就是在隔离性和性能之间不断地寻找更优的平衡点,不同产品在事务一致性上的差别,也完全体现在隔离性的实现等级上,SQL-92定义的隔离级别如下:
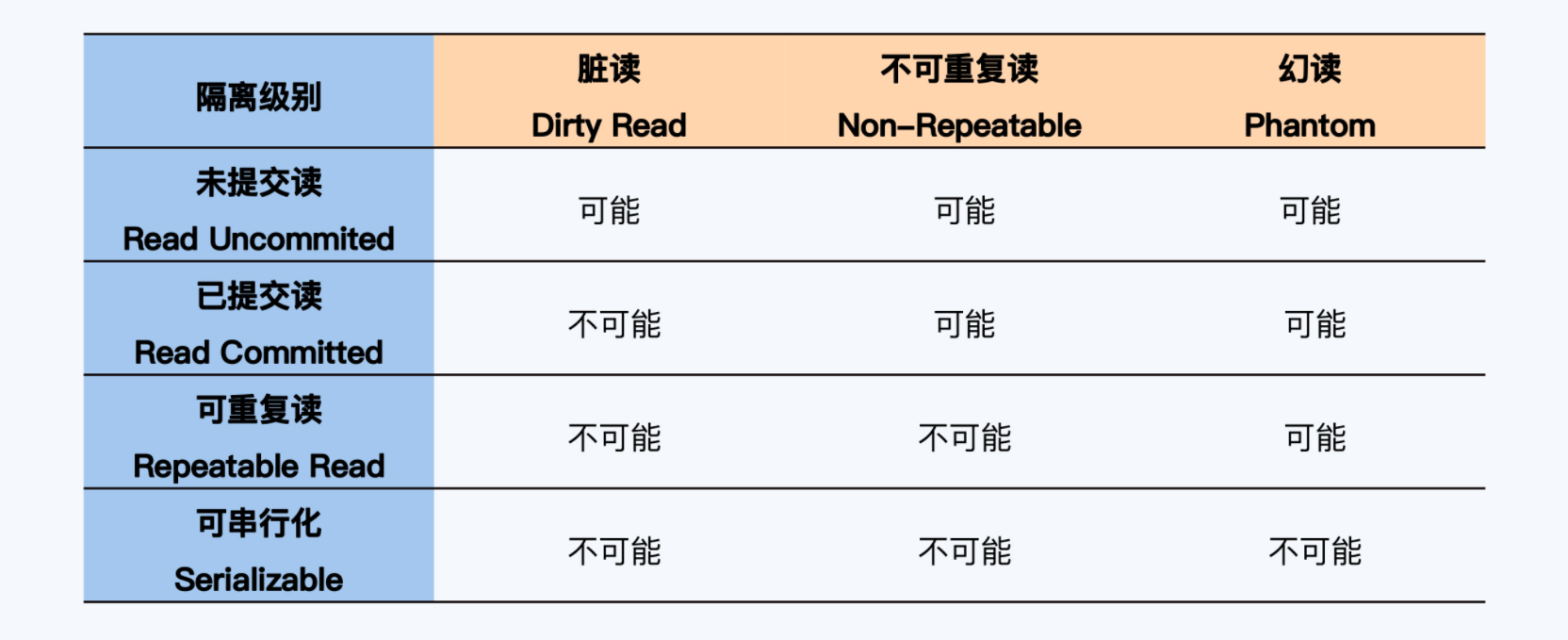
论文A Critique of ANSI SQL Isolation Levels定义了更严谨的隔离级别,细化了 SQL-92 的内容,定义了六种隔离级别和八种异常现象。